KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler

Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-Cluster and Multicloud GPU Provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Region
Global
Industry
Industry Cloud Computing
Company Size
10,748 (2024)
Optimizing Compute Costs and Performance with Smart Scaler
Finvi is a leading financial technology company known for its innovative revenue recovery solutions that serve clients across healthcare, accounts receivable management, and financial services. Its flagship application, a robust revenue acceleration platform, supports thousands of users and handles dynamic workloads across time zones and customer segments.
Challenges
The Akamai team needed a solution that could:
- Resource Over-Provisioning: To accommodate peak usage periods, Finvi often over-provisioned compute resources, resulting in underutilization during off-peak times and increased operational expenses
- Manual Scaling Limitations: The existing manual scaling processes were reactive and lacked the agility to respond promptly to sudden traffic spikes, affecting application performance and user experience.
- Cost Management: Finvi’s cloud infrastructure costs continued to rise, prompting a need for a more intelligent and automated approach to scaling that could preserve performance while reducing waste.
The Solution: Smart Scaler by Avesha
To address these challenges, the company implemented Smart Scaler, an AI-augmented predictive autoscaling solution. Smart Scaler integrates seamlessly with existing cloud environments, offering intelligent scaling capabilities for both application and infrastructure resources.
Implementation Steps
- Integration with Monitoring Tools: Smart Scaler was configured to work alongside Finvi’s existing Application Performance Monitoring (APM) tools, such as Prometheus and DataDog, to gather real-time metrics on application performance and traffic patterns.
- Predictive Autoscaling Configuration: Utilizing machine learning algorithms, Smart Scaler analyzed historical data to forecast traffic demands accurately. This predictive capability enabled proactive scaling of compute resources, ensuring optimal performance during peak periods and cost savings during low-demand intervals.
- Dynamic Resource Allocation:
The solution facilitated automatic adjustment of both pods and nodes within the Kubernetes cluster, aligning resource allocation with anticipated workloads. This dynamic approach minimized manual intervention and reduced the risk of over-provisioning.
Results
- Cost Reduction:
By implementing Smart Scaler, Finvi achieved up to a 70% reduction in cloud infrastructure costs. The intelligent scaling mechanism ensured that resources were utilized efficiently, eliminating unnecessary expenditures associated with idle resources. - Enhanced Performance:
The predictive autoscaling feature allowed the application to maintain consistent performance levels, even during unexpected traffic surges. Users experienced improved response times, leading to higher satisfaction and retention rates. - Operational Efficiency:
Automation of the scaling process reduced the operational burden on IT teams, allowing them to focus on strategic initiatives rather than routine infrastructure management tasks.
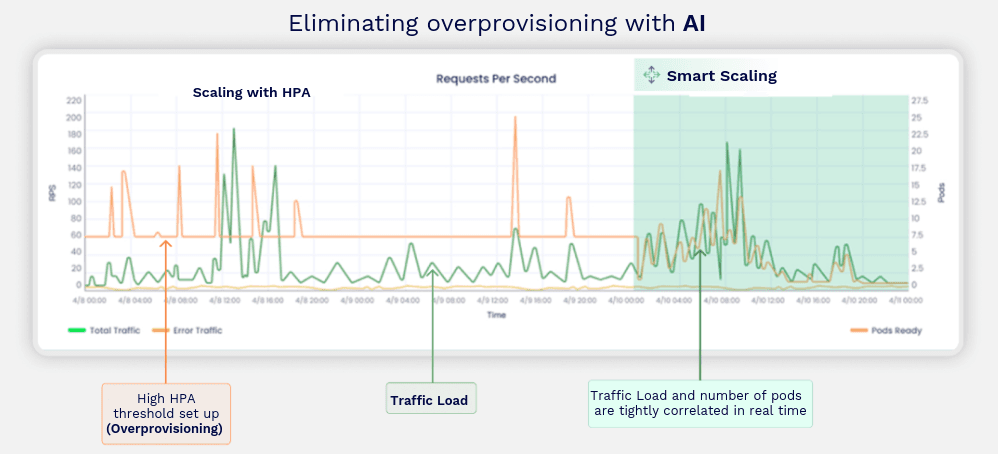
Explanation: The chart compares traditional HPA-based autoscaling with Smart Scaler. While HPA requires high thresholds to trigger action - often leading to overprovisioning - Smart Scaler (the green shaded area on the right) maintains a tight correlation between traffic load and pod count in real time, ensuring just-in-time resource scaling and preventing waste.
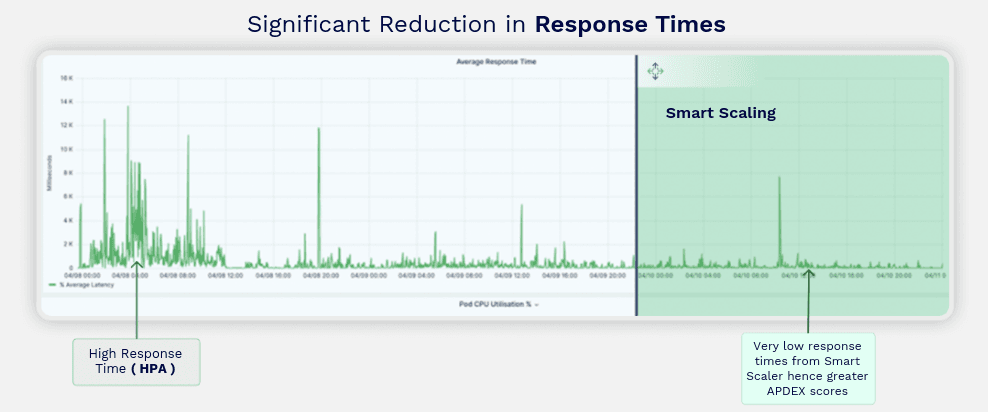
Explanation: With Smart Scaler, Finvi experienced a dramatic drop in response times. Unlike HPA, which reacts to load with delays, Smart Scaler predicts load and provisions resources ahead of time, delivering a smoother, faster user experience.
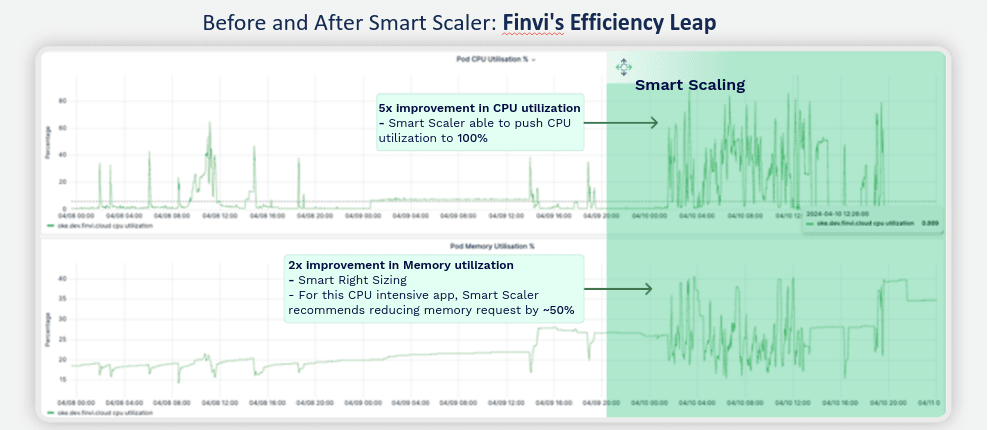
Explanation: Finvi saw a 5x improvement in CPU utilization, maximizing compute resource efficiency. For this CPU-intensive workload, Smart Scaler also recommended a 50% reduction in memory requests, achieving a 2x gain in memory utilization and further reducing costs
Conclusion
Smart Scaler transformed Finvi’s approach to cloud infrastructure management. Through intelligent, predictive autoscaling and real-time optimization, Finvi:
- Reduced cloud spend by up to 70%
- Increased resource utilization across CPU and memory
- Maintained exceptional performance under variable traffic
- Freed up engineering teams from infrastructure tuning
This case demonstrates how AI-driven automation with Smart Scaler can modernize infrastructure operations for any enterprise-scale application.















